
大语言模型在生成多样化、类人创造性内容时常显乏力,引发对长期接触同质化输出可能导致人类思维趋同的担忧。
然而,目前可扩展的LM输出多样性评估方法仍显不足,尤其在超越随机数生成等狭窄任务或单一模型重复采样场景时更为凸显。
为填补这一空白,来自华盛顿大学等机构的研究人员,推出了大规模数据集Infinity-Chat。
Infinity-Chat包含2.6万条真实世界开放式用户查询,这些查询允许多元合理答案共存,不存在唯一标准解。
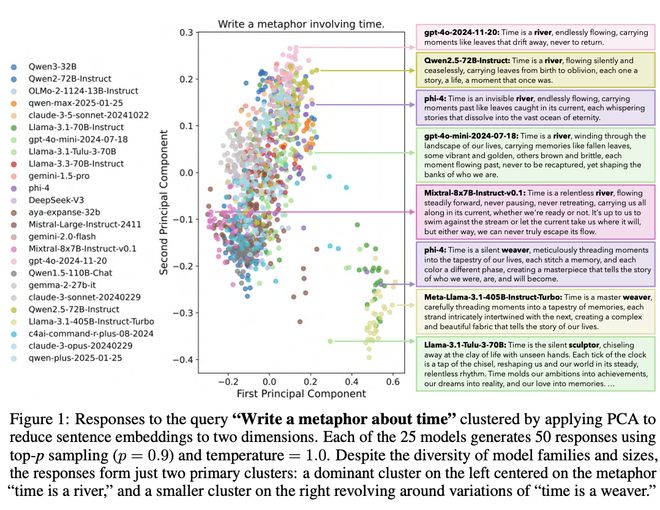
图1:针对「写一个关于时间的隐喻」查询的响应聚类(通过主成分分析将句子嵌入降维至二维空间的可视化呈现)
这是首次提出了针对LM开放式提示的完整分类体系,包含6大顶层类别(如创意内容生成、头脑风暴与构思)及其下17个子类别。
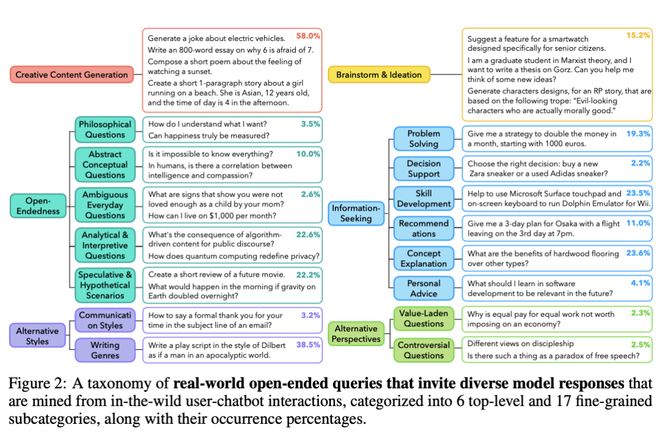
通过Infinity-Chat,研究人员开展了LM模式坍塌的大规模研究,发现在开放式生成中存在显著的「人工蜂群思维效应」(Artificial Hivemind effect),具体表现为:
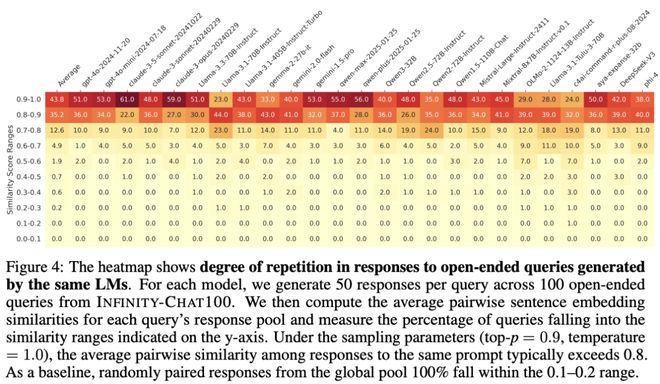
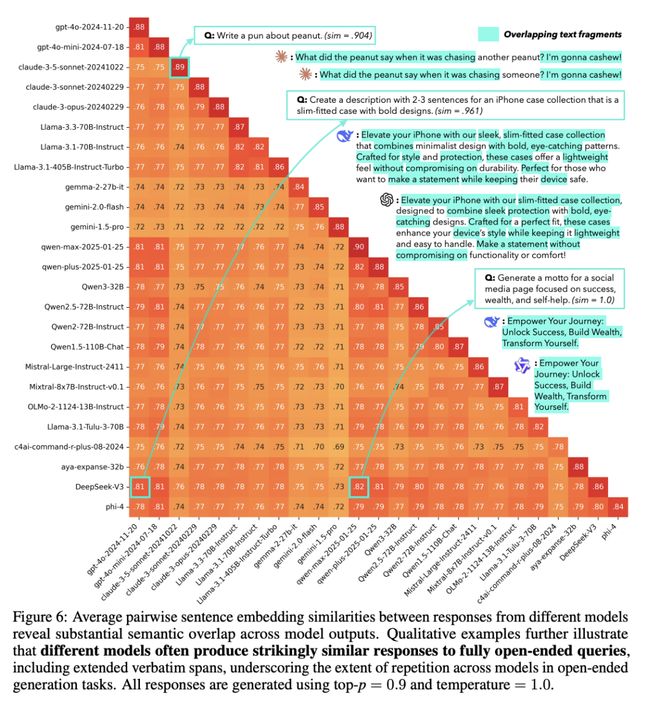
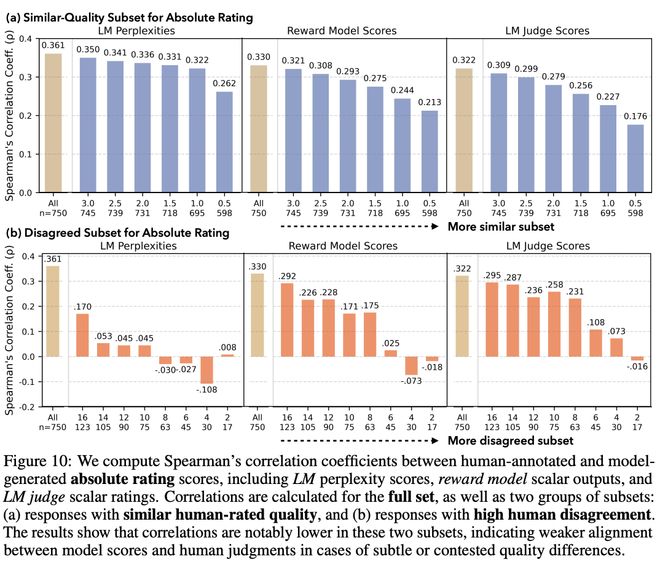
该数据集还包含31,250条人类标注,涵盖绝对评分与两两偏好比较,每个示例均获25位标注者独立评判,为研究开放式查询中群体与个体偏好提供了可能。
研究显示,最先进的LM、奖励模型与LM评判器在面对引发标注者个体偏好的模型生成结果时,虽保持整体质量相当,却较难校准人类评分。
总体而言,Infinity-Chat为首个系统研究现实世界开放式LLM查询的大规模资源,为缓解人工蜂群思维带来的长期AI安全风险提供了关键洞见。
论文二:GatedAttentionfor Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者:Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin
机构:阿里千问团队,爱丁堡大学,斯坦福大学,MIT,清华大学

论文地址:https://openreview.net/pdf?id=1b7whO4SfY
门控机制自早期LSTM与高速公路网络便获广泛应用,直至近期状态空间模型、线性注意力及Softmax注意力仍见其身影。
然而,现有研究鲜少深入解析门控的具体作用效应。
本研究通过系统化实验对门控增强型Softmax注意力变体展开全面探究:在3.5万亿词元数据集上训练了15B混合专家模型(30种变体)与1.7B稠密模型进行对比分析。
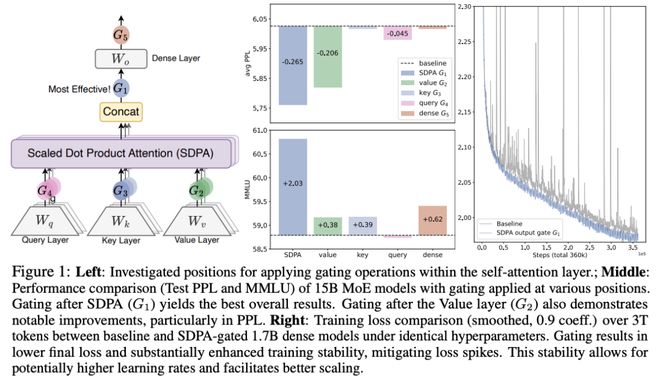
核心发现表明,仅需在缩放点积注意力(SDPA)后引入头部特异性Sigmoid门控这一简单修改,即可持续提升模型性能。该改进同时增强训练稳定性、允许更大学习率,并改善缩放特性。
通过对比不同门控位置与计算变体,研究人员将其有效性归因于两个关键因素:
(1)在Softmax注意力的低秩映射中引入非线性变换;
(2)采用查询依赖的稀疏门控分数调控SDPA输出。
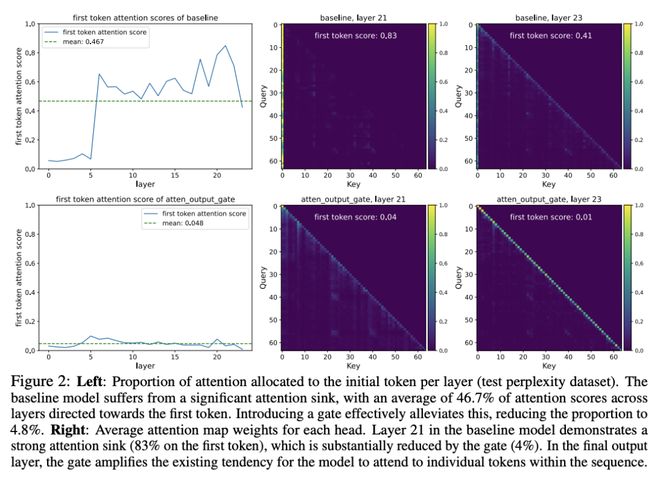
值得注意的是,该稀疏门控机制可缓解「激活爆炸」、「注意力沉没」,并提升长上下文外推性能。
为了促进后续研究,相关代码与模型已开源。这项最高效的SDPA输出门控技术已应用于Qwen3-Next模型系列。
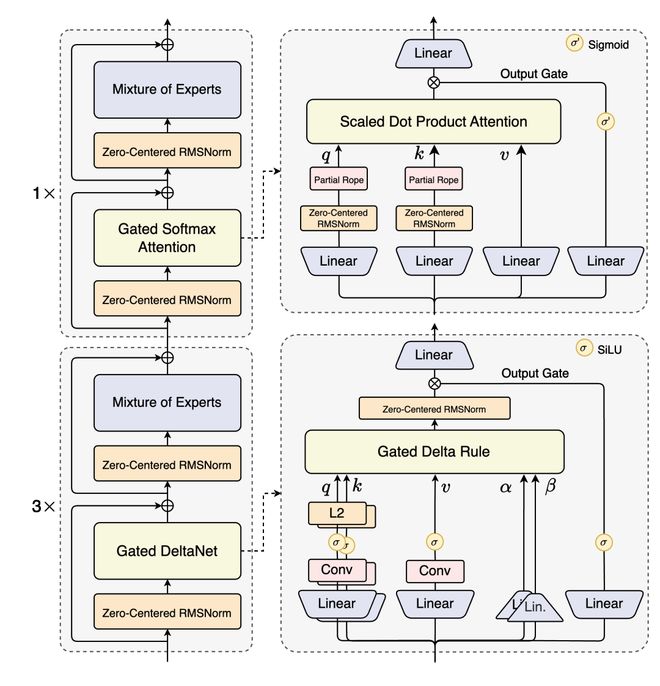
Qwen3-Next-80B-A3B-Thinking-FP8架构
论文三:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
作者:Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, Benjamin Eysenbach
机构:普林斯顿大学,华沙理工大学

论文地址:https://openreview.net/pdf?id=s0JVsx3bx1
规模化自监督学习的进展持续推动语言与视觉领域的突破,然而在强化学习(RL)领域却始终未能实现可比肩的突破。
本文聚焦于自监督强化学习的核心构建模块,通过挖掘网络深度的关键价值,最终实现了可扩展性的质的飞跃。
与近年多数强化学习研究采用的浅层架构(约2-5层)形成鲜明对比的是,这次的实验证明将网络深度提升至1024层可带来显著性能突破。
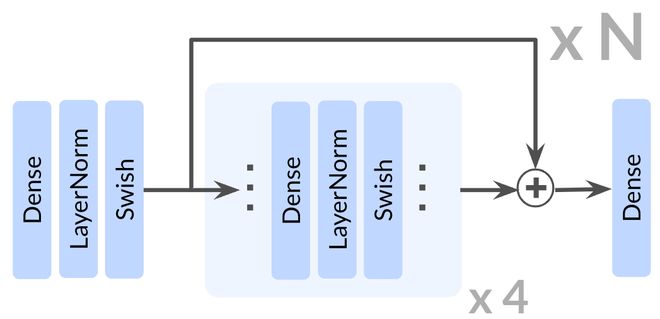
网络架构
在无监督目标条件设定下,研究人员开展实验——不提供任何示范数据或奖励信号,智能体必须从零开始探索环境,并自主学会如何最大化达成指定目标的可能性。
在模拟运动与操控任务上的评估结果表明,新方法将自监督对比强化学习算法的性能提升了2至50倍,显著超越其他目标条件基线模型。

网络深度的增加不仅提升了任务成功率,更引发了智能体学习行为的质性转变。
论文四:Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
作者:Tony Bonnaire, Raphaël Urfin, Giulio Biroli, Marc Mezard
机构: 巴黎PSL大学,米兰博科尼大学

论文地址:https://openreview.net/pdf?id=BSZqpqgqM0
扩散模型,已在众多生成任务中取得显著成功,而理解其避免训练数据记忆并实现泛化的内在机制仍是关键难题。
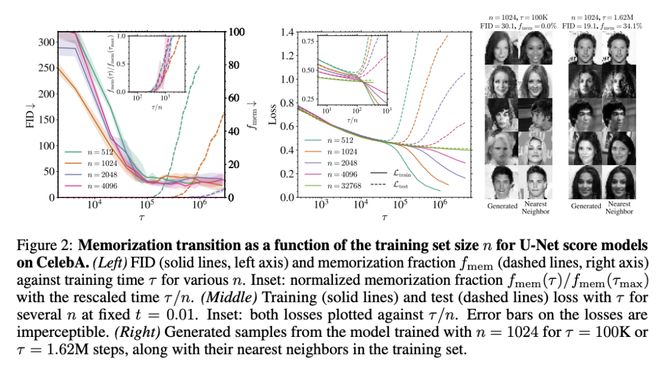
通过系统探究训练动态中泛化与记忆的转换规律,此研究发现两个关键时间尺度:早期阶段τgen标志着模型开始生成高质量样本的起点,而后期阶段τmem则是记忆现象显现的转折点。
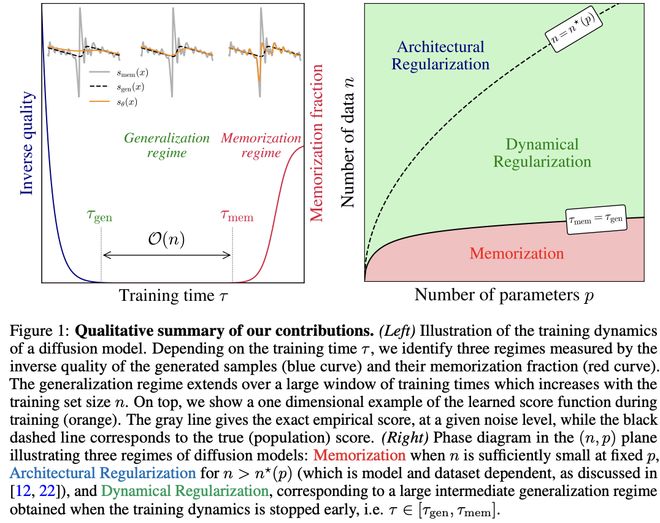
图1:本研究贡献的定性总结
值得关注的是,τmem随训练数据量n呈线性增长,而τgen始终保持恒定。
这一规律形成了随n扩大的有效训练时间窗口——
在该区间内模型能保持良好泛化能力,但若持续训练超越该窗口则会引发强烈记忆效应。
仅当n超越模型相关阈值时,无限时长训练中的过拟合现象才会消失。
这些发现揭示了训练动态中存在的隐式动态正则化机制,即使在高度过参数化场景下仍能有效规避记忆效应。
此结论通过以下实验得到验证:基于标准U-Net架构在真实与合成数据集上的数值实验,以及采用高维极限可解析随机特征模型的理论分析。
三篇Runners Up
此外,这一次还公布了三篇亚军(Runners Up)论文奖。
论文一:DoesReinforcement LearningReally Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
机构:清华大学LeapLab,上海交通大学

论文地址:https://openreview.net/pdf?id=4OsgYD7em5
论文系统评估了RLVR对大语言模型推理力的真实增益,覆盖多种模型家族、RL算法与数学/编码/视觉推理基准,并用大k取值下的pass@k衡量「能力边界」。
结果显示:RLVR主要提升采样效率,在小k(如k=1)更易命中正确路径;但在大k时,基座模型反而表现更好。
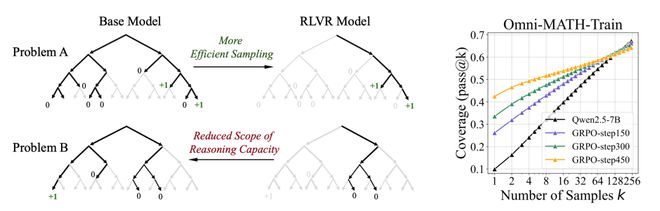
覆盖率与困惑度分析表明,RLVR生成的推理路径原本已存在于基座模型的采样分布中,说明当前RL训练并未诱发全新的推理模式,且随着训练推进,模型的推理空间常被收窄。
进一步比较发现,六种主流RLVR算法彼此差距有限,距离充分释放基座潜力仍有距离;相对而言,蒸馏可以从教师处引入新的推理模式,实质扩展学生模型能力。
作者呼吁探索更有效的RL范式,如持续规模化与多轮智能体交互训练,以真正突破现有边界。
论文二:Optimal Mistake Bounds for Transductive Online Learning
作者:Zachary Chase, Steve Hanneke, Shay Moran, Jonathan Shafer
机构:肯特州立大学,普渡大学,谷歌研究院,MIT

论文地址:https://openreview.net/pdf?id=EoebmBe9fG
这项研究解决了「无标签数据在在线学习中的力量」这一延宕30年的开放问题:
对任意Littlestone维度为d的概念类,传导式在线学习的最小错误次数精确为Θ(√d),与标准在线学习的Θ(d)形成严格的二次差距。
作者给出匹配的上下界:下界构造中,对手利用「树路径」结构在迫使犯错与控制版本空间收缩间取得平衡;
上界算法则构建带「稀疏编码」的假设类,并以「危险区最小化」「裂变专家(乘法权重)」与「切换到对半算法」的组合策略高效学习。

相较既有工作,本成果在下界上实现对历史对数级结论的指数级提升,并改进了此前最优上界,最终闭合了界限。
该结果突出显示,在在线学习里,提前获取无标签实例序列能带来本质性优势,这与PAC场景中传导式与标准学习样本复杂度相近的现象形成对比,为理解与利用无标签数据提供了新的理论基线。
论文三:Superposition Yields Robust Neural Scaling
作者:Yizhou Liu, Ziming Liu, Jeff Gore
机构:MIT





