
我去,一进入 11 月就有大惊喜。
今天看到 Lovart 开始支持图层编辑功能,相当炸裂,绝对会成为近几年 AI 图像领域的一个关键里程碑事件。
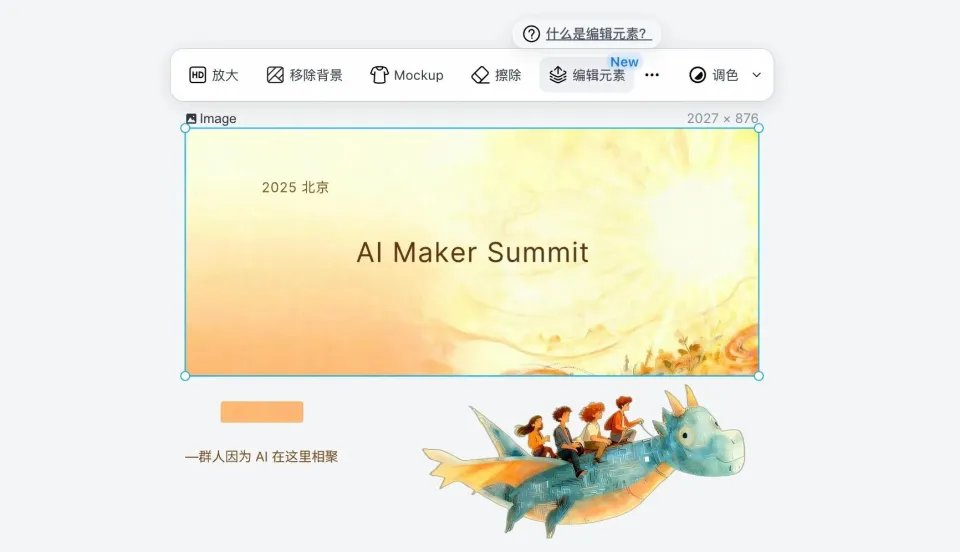
过去,如果你在业务中,带着一个真实的目标,使用 AI 图像能力的话,会知道 AI 很擅长生成图片,但编辑层面却一言难尽。
比如最近团队做一个新产品,我定了一个原则:所有的图片必须通过 AI 搞定,不能再找兼职的设计同事。但能看出来,大家确实比较吃力,抽卡抽得头秃。
下面这是我同事的上周五修改一个 Banner 图的工作流截图:

虽然 Nano Banana、Seedream 4.0 这些模型在图像修改方面已经做得很强了,但本质上,它还是通过自然语言的方式修改,这种方式的缺点是很难精确控制。
所以大家最后找的折中办法是,让 AI 先生成一个符合我们预期的背景图出来,然后再拿到 Photoshop 中,手动添加文字和其他微小的元素。
这是我们最近一个月摸索出来的最佳实践。但说实话,很费劲,效率不高。
其实修改一个图片中字体的样式,最简单的方式就是像 Photoshop 那样选中字体,然后手动调整。
可惜的是,之前因为技术难度,没有哪个 AI 能做到这种水准。所有的模型输出的都是一张 JPG 样式的平面图,而非可以编辑的 PSD 文件。
只要和我们团队一样,用 AI 做过真实业务场景中的图片,我猜都会遇到类似的问题。很简单的修改,AI 就是弯弯绕绕搞不定。甚至不耐烦的时候,你都想拍桌子发泄下。
有时候用自然语言,就是很难说清楚。鸡同鸭讲的感觉。一遍一遍的抽卡,结果等来的全是失望。
所以,听说 Lovart 支持分层图像编辑功能后,我马上上手试了试。简单说,它可以让我们像 Photoshop 那样自由地调整图片中的元素,而且图像的细节和完整性不会受到影响。
操作很简单。上传或者生成一张图后,点击编辑元素按钮,Lovart 会自动理解图像里都有哪些组成部分,比如人物、背景、文字、建筑等,再把这些元素拆分成不同的图层。
我们可以单独选中人物图层,把他往右挪一点;也可以调整字体层的颜色和大小;或者改背景光影,而不影响前景人物。这一切都能通过提示词或者拖动来实现。
下面这是我们录的一个屏,大家感受下。
然后我们就可以像 Photoshop 那样调整文字的字体、颜色、边框。或者觉得某个元素不行,那就直接把它挪走。
太强了。我觉得我们这次,真的可以不用再给 Photoshop 续费了。
说到 Photoshop,再吐槽下 Adobe 这家公司。前两天他们刚发布了新的图片模型 Firefly Image 5,同样支持分层图像编辑功能。
我刚还准备对比下它和 Lovart 谁做得好一些。结果,登录网站后,找半天没找到入口。
用 Deep Research 查了下才知道,他们发的是期货。什么时候上线都没定。真服了。

Lovart 这个技术非常牛 X,他们团队目前还没有公开相关的技术细节。
搜了下,我找到一篇 2024 年的论文,大概也是研究这个方向。
但不知道为什么过去这几年里,像谷歌、OpenAI、Midjourney 这样的公司都没实现类似的能力。按说这是众人皆知的刚需功能。

当然,Lovart 的功能目前也还有 Bug。
比如在含有手写字体的图片中,分层后整体的一致性保持得还不够理想。
像下面这个视频里我们测试的案例,手写文字在分层过程中出现了轻微的走行,字重和线条粗细都有变化。
不过,已经很完美了。可以 100% 确定,这些小 Bug 随着时间推移,一定都能解决。
我兴奋的是,现在,所有图片都可以编辑了。这绝对是视觉工作流里的一个巨大跨越。
过去几十年,想修改 JPG 之类的图片,我们能做的就是抠、涂、遮、重画。这是 Photoshop 在上个时代的创新。比如:想把人往右挪一点?要抠人、补背景。想改字体?只能盖掉重写。
除非,我们有 PSD 文件。
即便美图秀秀之类的产品降低了 Photoshop 的门槛,但它也没有改变本质。而且用过的人都知道,对于严肃场景而言,美图秀秀还是不够专业和精细。
我是这么理解的:在 Photoshop 或者美图之类的图片软件中,JPG 意味着扁平的像素输出。每个像素都是独立的,没有逻辑关系。本质上,工具没办法理解图像。
而 Lovart,它可以借助 AI 能力,充分理解图的内容。它知道,哪些是前景,哪些是背景;哪个部分是文字、人物、物体;哪些区域属于同一个语义单元。
在理解的基础上,再把这些部分自动拆成图层,形成一个可重新编辑的结构。这样,文字就可以直接修改,人物就能够快速挪动,画面中的构图关系可以重新调整。
以前我们是在修图,现在是能真正地编辑图片了。
除了上线分层图像编辑,Lovart 又火速接入了两款最新的视频模型:Hailuo 2.3 和 LTX 2。
Hailuo 大家应该熟悉,国内创业公司 MiniMax 出品的视频模型,这次更新它在写实的内容方面有明显提升。
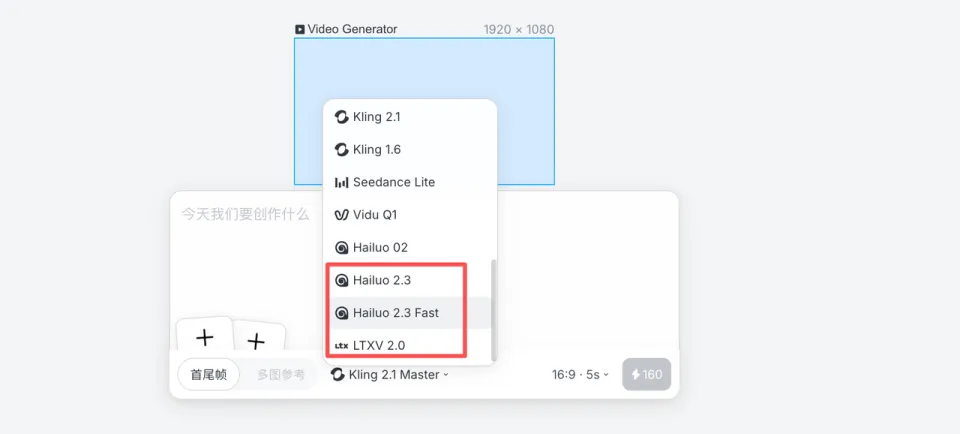
LTX 2 估计听过的人少,它是以色列公司 Lightricks 推出的视频模型,亮点是速度极快,一个 20 秒、1080p 的电影视频,30 秒之内就能够生成,而且质量也很不错。
输入了一个跑酷的提示词,下面是 Hailuo 2.3 的效果:
下面是 LTX 2 的效果。它最高可以生成 2160p 的视频。
当然,结合前面图片编辑的功能,我也有点期待 Lovart 什么时候能支持视频编辑。
如果有一天,我们能像编辑图片那样编辑视频,那视频的制作门槛,又会进一步降低。真是一个创作娱乐化的时代啊。
想想挺神奇的。
也就是上周,我们还在为一张海报反复抽卡、改提示词。周五晚上我们下班很晚,我看着团队同学加班,内心有点沮丧,也怀疑自己之前的决策。
是不是目前 AI 生图还没办法适应真实场景的需求,是不是从效率的角度,还是请专门的设计师来做比较好?我内心在左右横跳。
没想到,也就周末休息了两天,这些阴霾就被技术的洪流一扫而空。
何其有幸,能亲眼见证这样的时代。所以我很珍惜,也愿意为 Lovart 这样的产品付费。
不是因为它完美,而是因为它代表着一种新的可能。它让我有机会,真正接住这个时代滚烫的技术红利。




