
昨天有一个有趣的事,真的太魔幻了,感觉剧本都不会写的这么巧。
就在昨天晚上,DeepSeek悄悄地上了一个新模型,DeepSeekMath-V2。
一个基于DeepSeek-V3.2-Exp-Base构建的685B的数学专用模型。
这个模型特殊的点,说人话就是,它不仅能给出答案,还能自己检查自己的解题步骤,自己给自己挑错,自己跟自己辩论,直到它自己觉得自己整个推理过程,完美无瑕。
而且,能力上,达到了奥林匹克金牌水平。
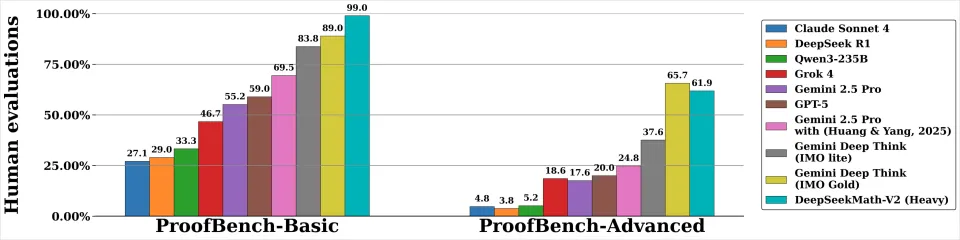
并在 IMO 2025(解决了 5/6 道题)和 Putnam 2024(接近满分 118/120 分)等竞赛中表现出色。
同时,按照DeepSeek传统,直接开源+送论文。
论文名字很直接:《DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning》。
而我之所以说魔幻的原因在于。
就在2天前,大洋彼岸,被誉为AI教父之一、前OpenAI首席科学家Ilya Sutskever,刚刚出来发声,录了一期播客。
在这期播客里,他抛出了一个非常有意思的担忧。
就是,现在的AI模型很奇怪。
一方面,它们在各种评测集上刷出了逆天的分数,什么考试、什么竞赛,都能名列前茅。
但另一方面,你把它扔到真实世界里去解决实际问题,它又蠢得让人想砸电脑。
他举了个例子,特别写实:
就是你让AI帮你修一个代码里的bug A,它说“好嘞”,然后给你引入了一个新的bug B。
你再让它修bug B,它又说“没问题”,然后转身就把bug A又给改回来了。
就这么来来回回,修了半天修不好,我相信大家玩vibe coding的人,都遇到过这个问题。
Ilya自己一直在思考,为什么会这样?为什么评测表现和真实世界表现之间,有这么大的鸿沟?
他在这个播客里面,给出了一个非常深刻的类比。
他说,现在的AI模型,就像一个特长生A,这个学生的目标呢,就是成为最牛逼的算法竞赛选手。
于是他花了一万个小时,刷遍了所有竞赛题,背熟了所有解题技巧。最后,他确实成了这个领域的王者。
但还有一个通才生B。他对竞赛也感兴趣,但只花了100个小时去练习,成绩也不错。
但他把更多的时间,花在了理解世界、广泛阅读、与人交流这些务虚的事情上。
Ilya问:这两个学生,谁未来的职业发展会更好?
答案不言而喻,是学生B。
因为学生A的强大,是一种应试的强大。
他的所有能力,都是为了在评测中拿高分这个单一目标而优化的。这种训练,就像把一个人的视野强行压缩成一根针,他在这根针里能看到原子,但在针以外的世界,他是个盲人。
而学生B,他拥有一种更可贵的东西,Ilya也不知道该怎么描述,所以他的原话就是“那股劲儿”(the “it”),一种更深刻的、更具泛化性的理解力。
所以,最后就会导致,经过重度 RL 对齐的模型往往显得更笨或更缺乏创造力,RL强行让 AI 去讨好人类的某个单一指标,却可能牺牲了它原本宽广的通用智力。
其实最近一些大模型,比如GPT-5、Gemini 3 Pro在写作能力上的下降,我觉得就能看出一些端倪了。
Ilya的这段话,还是引起了非常大的反响的。
然后,就在这个问题还余音绕梁的时候,DeepSeekMath-V2来了。
直接说,我搞定了。
特别有意思。
可以说,DeepSeekMath-V2,已经开始解决Ilya的一些担忧了。
在讲DeepSeekMath-V2之前,我觉得还是先有必要,来聊聊以前的AI是怎么做数学题的。超级简单,也超级粗暴。
就是,结果导向。
就像一个公司的销售,老板只看你月底的业绩报表,不管你这单子是怎么签下来的。你用尽九牛二虎之力,还是用了一些肮脏的手段,还是瞎猫碰上死耗子,无所谓,只要最后那个数字是对的,模型就能得到奖励。
这种模式,在做一些简单的计算题时,问题不大。
但一旦涉及到复杂的证明题,就彻底废了。
我相信大家上学时肯定也都被数学老师折磨过,我自己最常听到的一句话,就是。。。
“答题是看过程的!你的过程呢?!”
一道大题15分,答案可能只占2分,剩下13分,全在过程里。

你就算最后答案蒙对了,过程一塌糊涂,照样拉跨。
因为数学这门学科,从本质上来说,它追求的就不是那个最终的答案,而是那个无懈可击、一步一响的逻辑链。
是从公理这个地基开始,一砖一瓦,盖起一座真理的大厦。
中间任何一环有瑕疵,整个大厦都会崩塌。
之前的AI,就是这样的,你让他写出答案,他可能还真的没啥问题,但是你让他写证明过程,那就完特么蛋了,经常给你生编硬造。
甚至有时候,它给你的最终答案,是靠着某个计算失误+另一个逻辑错误负负得正,最后歪打正着搞出来的。
这就是过去AI的通病,你说他对了吧,他也真对了,但是你要是跟他在过程中较个真吧,那也经常错的离谱。
本质上,还是模型没有反思能力。
虽然模型有所谓的思维链,但是这个思维链,或者说这个逻辑,也分几个级别。
第一个级别,我称之为Prompt级cosplay反思。
就是你跟他说你要好好想一想,其实就是多写几句CoT,训练时根本没强约束它真的检查过,这个就不说了,纯文案。
第二个级别,就是OpenAI o1、DeepSeek R1等等,有自己的思维链的,这种其实可以称为,答案导向的反思。
这类所谓的“reasoning model”的典型套路其实就是,用RL来奖励最后答案对不对,可以允许模型在中间多想、多分支、自己评估几个方案,再选一个。
这套模式你不能说他不行,确实很强,通过奖励最终答案的正确,一年内,确实把AIME、HMMT这种只看答案的竞赛打满分。
但有两个硬伤。
1. 正确答案 ≠ 推理真的对,中间瞎算、走错路、蒙对都算赢。
2. 像定理证明这种题,根本没有单一数值答案可以奖励,所以也就容易拉了。
而第三个级别,就是这次的DeepSeekMath-V2,真正把过程当任务的反思。
这个点,也是源于DeepSeek对人的观察。

DeepSeekMath-V2的做法,也很有意思,甚至有点精神分裂的哲学味。
他们其实搞了两个AI出来。
一个叫生成器(Generator)。这哥们儿就是那个天马行空、才华横溢的学生。你把题给他,他奋笔疾书,洋洋洒洒,给你写出一套解题过程。
另一个叫验证器(Verifier)。这哥们儿是个极其刻薄、吹毛求疵、毫无感情的老师。生成器写完的每一个字,都要经过它的审判。它就像拿着放大镜一样,逐行检查,寻找任何可能的逻辑漏洞、计算错误、概念不清。
然后,他们让验证器去当生成器的老师。生成器每写完一步,验证器就在旁边打分:
“你这里逻辑不严谨,扣分。”,“你这个公式用错了,扣分。”,“你这里跳步了,扣分。”
“生成器”为了得到老师也就是验证器的表扬,就必须不断地修改、完善自己的证明过程。
它慢慢地就学会了,不能只图快,每一步都得想清楚,都得有理有据。
经过这种反复的自我搏斗,AI就不再是一个只会输出答案的机器了。
它开始拥有了一种真正的最宝贵的能力:
“反思”。
这个能力,也让DeepSeekMath-V2在证明题的能力上,薄纱同行。
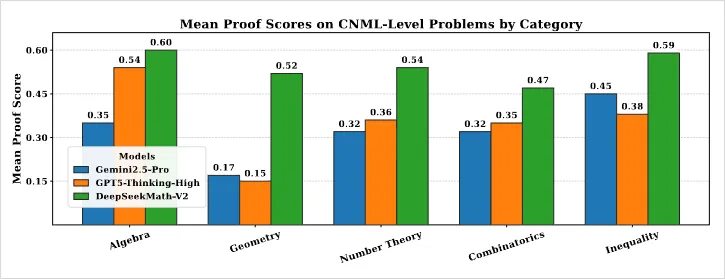
它不再盲目地相信自己的第一直觉。
在这个过程中,它学会了怀疑,学会了审视,学会了批判性思维。
而且,这还没完。
DeepSeek觉得,这还不够精神分裂。所以,他们又来了一个更狠的:
元验证(Meta-Verification)。
大概就是,就是他们又搞了个总教导主任,这个主任不去看学生的卷子,而是去看老师批改的卷子有没有问题。
毕竟有时候,验证器这个老师也会犯错。
比如它可能会冤枉一个好学生,把对的步骤判成错的,或者自己老眼昏花,没发现学生隐藏得很深的错误。
元验证器的作用,就是确保验证器的每一次评判都是公平、准确、有效的。
这套组合拳下来,就形成了一个极其强大的正向循环:
1. 生成器努力写出更完美的证明。
2. 验证器在元验证器的监督下,变得越来越准确。
3. 更强的验证器又能反过来训练出更强的生成器。
左脚蹬右脚,螺旋登天。
最终,他们把这两种能力,合二为一,注入到了同一个AI的身体里。于是,DeepSeekMath-V2诞生了。
再看看它的成绩。
IMO(国际数学奥林匹克竞赛):这是全世界高中生的最高殿堂。DeepSeekMath-V2在2025年的模拟赛里,6道题解出了5道。金牌水平。
CMO(中国数学奥林匹克竞赛):中国最顶尖的数学竞赛。它也拿到了金牌水平的成绩。
最恐怖的是这个:Putnam Competition(普特南数学竞赛)。
这个竞赛,是全世界大学生数学竞赛里,公认的地狱难度。
它的题目,出的极其刁钻、深刻,因为难度过大,所以中位数得分通常为0或1分,而满分,是120分。。。。
说实话,在这种竞赛里,能考个十几二十分,就已经是人中龙凤了。
而去年的人类最高分,是90分。

而DeepSeekMath-V2的得分。
118分。
在12道题里,它完整、严谨地解出了11道,还有1道也拿到了大部分分数。
太离谱了。
这就是知道学会反思,学会过程以后的,真正的AI的实力。
不知道为什么,让我想起了Alpha GO。。。
DeepSeek这篇论文,实际上是给Ilya的问题,提供了一个可能的答案:
也许,要弥合评测与现实的鸿沟,我们不应该再给AI增加更多的外部RL环境去刷题,而是应该教会AI一种向内看的能力。
让它从追求让别人满意(获得奖励),转变为追求让自己满意(逻辑自洽)。
王阳明的心学,其实很早就提过这个观点。
心即理,真理不在外部,而在我们每个人的内心。
真正的学习,不是向外寻求标准答案,而是向内致良知,达到一种内在的和谐与通透。
DeepSeekMath-V2,就是AI领域的一次非常有趣的,“致良知”。
有的时候我经常在想,人类的理性,到底是什么?
康德觉得,理性是人类为自然立法的能力。我们通过先验的逻辑框架去理解、整理这个混乱的世界。
我感觉,DeepSeekMath-V2,有一点像。
过去我们总觉得,AI的智能和人类的智能,隔着一道鸿沟。
我们的智能里,有灵感、有顿悟、有情感、有那些说不清道不明的“Aha Moment”。
可也许,人类的灵感,只是我们大脑在算力不足的情况下,为了走捷径而产生的一种逻辑的跳跃。
而AI,正在用我们无法想象的算力,把我们跳过的每一步,都踏踏实实地走一遍。
它走的,是一条更慢、更笨,但可能也更接近本质的道路。
我们,这些习惯于跳跃的物种,站在AI这条坚实的逻辑长梯面前,难免会感到一丝震撼,和一丝……迷茫。
那我们未来的位置。
又在哪里呢?




