

投稿作者:黎羿江(UC San Diego 二年级博士生)
过去两年,生成式人工智能(AI)的浪潮席卷全球。从 ChatGPT 到 Claude,再到国内的 GLM、通义千问、文心等,大语言模型(LLM)已成为推动 AI 发展的核心引擎。
它们能写论文、写代码、生成故事,甚至参与科研。但与此同时,研究者逐渐发现了一个根本性问题:
这些模型虽然能生成高质量语言,却并不具备真实的行动能力。当模型面对需要计划、工具使用或环境交互的任务时,它们往往显得无能为力。
如何让语言模型不只是“回答问题”,而是能够“自主执行任务”?这是当前人工智能研究中最具挑战性的问题之一。
近期,由来自 Oxford、UCSD、NUS、ICL、UIUC、UCL、上海人工智能实验室等十六家顶尖机构的学者联合完成的一篇综述论文给出了系统性的答案。

论文链接:https://arxiv.org/abs/2509.02547
开源项目:https://github.com/xhyumiracle/Awesome-AgenticLLM-RL-Papers
这篇长达百页的综述整合了超过 500 篇相关研究,首次对 Agentic Reinforcement Learning(具身智能体强化学习)的概念、框架和应用进行了系统梳理。
从被动响应到主动决策:Agentic RL 的核心思想
在传统的强化学习(RLHF、DPO 等)中,语言模型被设计为“单步响应系统”。它接收输入,生成输出,并根据人类反馈或偏好调整参数。这种范式的代表就是 ChatGPT 的训练方式。
然而,这一机制只适用于单轮优化,无法处理需要长期规划和环境交互的任务。
Agentic RL 则提供了一种全新的视角。该框架将大语言模型视为嵌入在动态环境中的智能体(Agent),通过强化学习机制,让模型具备持续感知、连续决策、工具使用与自我优化的能力。
研究者将这一过程形式化为部分可观测马尔可夫决策过程(POMDP):模型可以在不完全了解环境的情况下,基于当前信息进行决策、执行行动,并通过反馈信号持续更新策略。
换言之,Agentic RL 的目标不是让模型“生成更好的答案”,而是让它“学习如何行动以实现目标”。
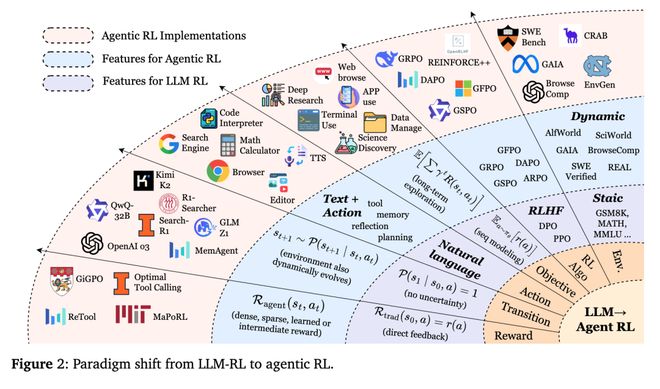
六大关键能力:从语言到智能的跃迁
论文中提出,真正的智能体必须具备六项核心能力,这也是 Agentic RL 的构成基础。
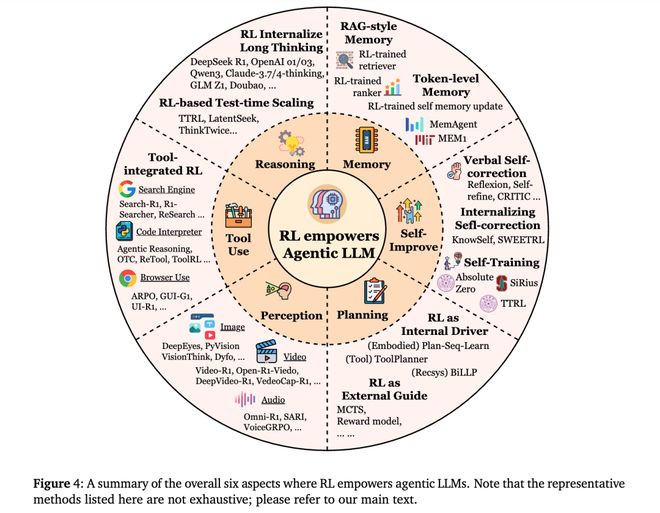
规划(Planning)
模型能够拆解复杂任务,制定多步行动计划,并根据反馈动态调整路径。 例如,科研助理可以自动规划文献检索、数据分析和论文撰写步骤。
工具使用(Tool Use)
传统方法依赖人工提示调用外部工具,而通过 RL,模型可以自主判断何时调用搜索引擎、代码执行器或数据库查询接口。
记忆(Memory)
Agentic RL 让模型在长期交互中保留关键信息,并学会“什么值得记住”。 这类记忆机制不仅包括显式文本记忆,还包括隐式向量表征与语义检索。
推理(Reasoning)
模型可以根据任务需求在“快速直觉推理”与“深度链式推理”之间切换。 强化学习通过奖励信号引导模型生成更稳定、更具逻辑一致性的推理路径。
自我改进(Self-Improvement)
智能体能够通过经验积累进行反思、自我修正,形成闭环学习机制。 例如,通过对错误输出的反思训练(Reflexion),模型的长期性能显著提升。
感知(Perception)
语言模型不再局限于文本输入,而是能够理解图像、音频、视频等多模态信息,并与外部世界建立联系。
这六个能力的结合,使得 LLM 从“被动语言生成器”迈向“主动学习与行动的认知系统”。
七类核心任务:Agentic RL 的应用版图
除了理论框架,论文还总结了 Agentic RL 在实践中的七大主要任务场景。
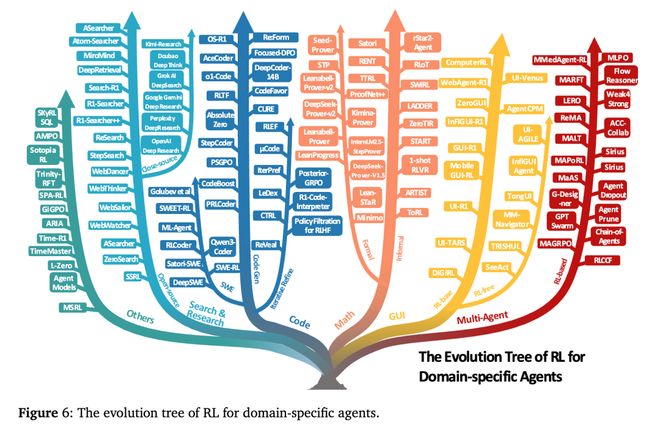
这些任务展示了一个清晰的趋势: Agentic RL 正在推动语言模型从“文字世界”走向“行动世界”, 让 AI 真正具备与现实环境交互的能力。
生态构建:开放环境与基础框架
论文还系统地整理了 Agentic RL 研究所依赖的开放环境、评测基准和训练框架。
作者团队还开源了一个综合资源清单:Awesome-AgenticLLM-RL-Papers,其中汇总了论文、环境、基准测试与开源实现, 为研究人员提供了从理论到实验的系统参考。
未来挑战与研究方向
尽管 Agentic RL 展现出巨大潜力,但仍面临若干挑战。
此外,智能体的伦理、安全与社会影响也成为研究的重要议题。Agentic RL 的发展不仅是算法创新,更是人类如何与智能系统共生的探索过程。
迈向智能体时代
Agentic RL 标志着语言模型研究从“生成”迈向“行动”的重大转折。它让模型不再依赖预设脚本,而是在环境中自主探索、持续学习,并根据反馈不断优化。
对于研究者,这一框架提供了新的理论基础与系统视角;对于开发者,它是构建具备决策与操作能力的 AI 系统的关键路径;对于整个 AI 生态而言,它意味着从“语言智能”走向“通用智能”的新阶段。
未来的 AI,不仅能对话、写作,更能观察、思考、执行与反思。Agentic RL 为这种真正意义上的“具身智能”打开了大门。





